はじめに
「ブルーアーカイブ」のキャラを操作して戦う、縦スクロール弾幕 STG を作りました。
PC ブラウザ上で遊べるので、未プレイの方はぜひプレイしてみてください。
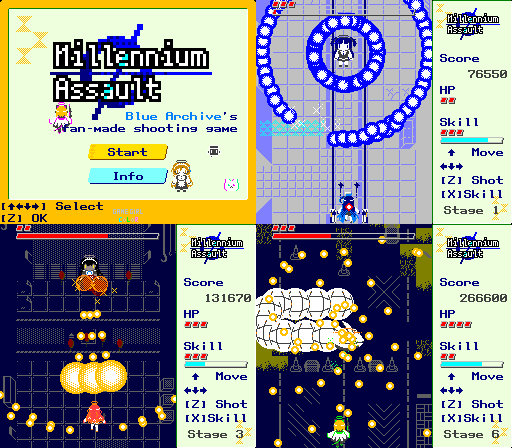
https://andanteyk.github.io/MillenniumAssault/
ここでは、開発の裏話等々を残していきたいと思います。
思いついたように書いているのでだいぶ読みにくいと思いますが、箇条書きぐらいの雰囲気で読んでください。
需要は考えません。書きたいので書きます…
発端
「ゲーム開発部」に関する作品を作ってタグをつけて投げると、プレゼントがもらえるかも… という公式さんのプレゼント企画です。
これを見て、「ちょっとやってみるかー」となりプロジェクトを作成したのが 04/18 です。
やろうと思えた要因としては、
- ゲーム開発部のイベント・キャラ等々が好きだった
- プログラミングならできるので、本当の意味で「ゲーム開発部」ができる
- (イラストとかに比べれば、の話なので、マサカリを投げないでくださいね…!)
- ゲーム開発部の設定が「レトロゲーム好き」であり、こちらもレトロチックにすれば
- テーマが一致して強い
- 私だけでもなんとかグラフィック(・サウンド)を賄うことができそう
- 締め切り (04/16 - 05/20) まで 1 か月はある
- イラスト中心の企画で 2 週間 とかだったら厳しかったでしょうね…
- 逆に、締め切りがなかったらそれはそれでリリースできなかったと思います。無限に延期できてしまうので…
- GW にまとまった休みがとれて、かつ大きな予定がなかった
という感じです。
始めるにあたり、ざっくり要件・目標を定めました。
- 基本的にすべて自分で作ること
- 具体的にはプログラム・グラフィック・サウンド(・プランニング)
- ライセンス周りが面倒で、かつ二次創作になるので、ややこしくなることは避けたかった
- (フォントとライブラリは流石に無理なので、正式な手段でお借りしました)
- 新技術のテスト・学習をすること
- せっかくなので、今まで使ったことのない・使い切れていないライブラリや Unity の新機能を試してみる
- 具体的には、
ゲームのジャンルについては、とりあえず弾幕系シューティングにするか、というのは決まっていました。
ゲームシステム自体の元ネタはお察しかと思いますが、 巫女さんと魔法使いのシューティング です。
理由としては、
- 工数がかかりにくそう (RPG とかに比べれば、ですが)
- はるか昔 (DxLib でしたね) に作ったことがあり、雰囲気は分かっていること
- ブルアカのテーマ (銃器を扱う) にマッチしていること
という感じです。
プラットフォームについては、今回は WebGL (ブラウザ上でプレイする形式) としました。
WebGL は試したことがなかったので、パフォーマンス上の問題や技術的制約に引っかからないか (一部の標準機能が封印されていたりします) 、といった懸念はありました。
ただ、言ってしまえば一発ネタなので、インストールの手間がかからず、すぐに遊べてすぐに終われるブラウザ上で完結する強さのほうが大きいのでは、と思い採用しました。
(実際この目論見はうまくいったような気がします。)
今回はソロ開発で「プログラム・グラフィック・サウンド・企画 私」状態だったので、「仕様はとりあえず作りながら考えるか」と見切り発車しました。
以降は各セクションの自分(?)からの所感や反省などです。
プランニング
ゲーム仕様レベルの設計思想や広報などを書きます。
自機
当初予定は「メイン双子、+αでアリス」だったのですが、いつの間にかユズさんが増えていました。おかげで Player Select 画面を作り直すことになりましたが、よしとします。
基本的には本編に沿ったり、スキルからの連想で作っています。
- モモイ: 広範囲型
- ミドリ: 狙撃型 (EX スキルから)
- アリス: 貫通型
- ユズ: 爆発型
元ネタのほうで見たことのある挙動だな、と思った方もいらっしゃるかと思いますが、概ねその通りの想定で作っています。
(流石に銃弾がホーミングするのはおかしいのでオートエイムにするか、とかはありますが)
アリスさんがレーザーなのは… 本当はレールガンではあるのですが、本編のエフェクトもレーザーっぽい感じなのでよかったのではないでしょうか。
バランス調整はかなり難しかったですが、まぁ細かいところは置いておいて DPS を概ね同じにしておこう、程度の方針でした。
アリスさんとユズさんは対ビナー特効を持っています(貫通・爆発して複数のボディにヒットするため)。アリスさんについては火力が高すぎがちになっていましたが、下げすぎると今度は道中や通常ボスで戦いにくくなってしまうので、まぁいいか、ということにしました。
ユズさんが塩梅が難しく、かなりピーキーな性能になってしまったのがちょっと心残りです。
爆風をもうちょっと広く or 強くしてもよかったかな、とか…
(でもあまり広くしすぎると多段ヒットしたりして強くなりすぎるので…)
クリア報告ツイートを見ると(本当にありがとうございます)、ミドリさんの使用率がかなり高いようでした。やはりオートエイムはつよい…!
操作系統については、「なるべくシンプルにしよう」というのは当初からありました。
最初期はもはやショットボタンすらなく、常にオートショット状態で「移動」と「スキル」だけあるような状態でした。
というのも、一応スマートフォンでも動作させられる余地を残しておきたかったからです。
敵の攻撃も、東方のように高密度な弾幕を撃ってきて低速+細やかな移動で避ける、というスタイルよりは、高速弾をちょっとした反射神経で避ける、というバランスにしよう、と(当初は)思っていました。
スマートフォンでは細やかな操作は絶望的であるのと、そもそも画面上に弾を出しまくると動作環境的に重くなる懸念があったためです。
まぁやっぱり押せたほうがいいよね、ということで、最終的には 移動・ショット・スキル の 3 系統になりました。
低速移動はショットと兼ねています。最初は常に等速 (現在のショット中と同じ) だったのですが、もともと自機の移動が遅めで爽快感がなかった・緊急回避が難しかったので、ノーショット時に加速 (x1.5) するようにしました。
スキルストックに上限がなくて画面をはみ出していくのは… 仕様です。
最初に気づいたとき、見た目がバグっぽくて面白い (ファミコンのころにありがちな感じな) のと、ユーザー有利なバグなのでそのまま仕様にしてしまおう、となった経緯があります。
ステージ
最初は「まぁ 3 面ぐらい遊べれば十分だろう」と思っていたのですが、 カリンさんとネルさんのスプライトを描いた際に「同じメイドなら多少増やしても工数が少ないのでは?」などと思ってしまい(そんなことはなく普通に大変でした)、アスナさんとアカネさんを追加しました。
これで 5 面 (ユウカさんと C&C 4人) になったので、せっかくだしあと 1 面… となり、ビナーを追加することにしました。
採用理由としては、
- 見た目が派手でシューティングゲームっぽい
- 実際、告知動画でも「映え」があったと思います。たぶん…
- ブルアカ本編で最初に戦ったボスなので思い入れがある
- (サウンドの都合上、戦闘 BGM がビナー戦のものだった)
蛇っぽい動きを作るのはなかなか難しかったですが、苦労に見合っただけの働きはしてくれたと思います。
あの動きは、 DOTween の Sequence を少しずつインターバルを入れて再生させることで実現しています。
例えば、頭は即時、次の体パーツは 0.1s 遅れ、次のは 0.2s ... といった具合です。
ビナーの動きといえば、開発初期は若干動きが怪しくて、ボディが一か所に固まってしまうことが多かったのです。
そうすると自機の弾が多段ヒットするようになり(ヒットで消滅する前に複数のボディに当たる)、耐久弾幕 (浄化の嵐) で無敵になる前の数秒間の隙にスキルを叩きこむことによって HP を削り切り、耐久弾幕をスキップできる… というバグがあって大変笑いました。マリス砲とか妹紅さんの使い魔とかそういったものが脳裏をよぎりました…
話を戻して…
道中の設計としては、以下に注意していました。
- 1 面はとにかく簡単にすること
- 操作に慣れさせるまで、しばらく弾は撃たない (撃ったとしても自機狙いではない)
- 開幕で離脱されると悲しいので… 退屈なぐらいでも構わない、としました。
- 工数を減らす(同じ動作・射撃設定の敵を使いまわす)
- スポーン位置を変えるだけで、ある程度別のムーブっぽく見えるようにはしました
- プレイヤーとしてもパターンが見えるようになるので、一応それらしくなります
ただ、コピペが続いてあまりにも単調になってしまったのと、雑魚の行動パターン作成にモチベーションがわかなかったため、開発後期に中ボスを導入しました。
これでバリエーションを増やしつつ、出来のよくない雑魚戦を削ることができました。
(実は中ボス戦の裏にも旧レイアウトの敵が配置されたままになっており、実際早く中ボスを撃破するとその敵が出てきます。中ボス出現中は雑魚の湧きをキャンセルするようにしています。)
近い理由で、6 面は道中がありません。楽をしたかったのと、即ビナーが出てくるインパクトがあって良いのでは、となったのがあります。
個人的にうまくいったかなと思っているのが 3 面の、中ボスカリン撃破後に画面外から狙撃されるところです。
シチュエーション的にそれっぽく、かつ "caution!" のインパクトがある(しかし脅威ではない)ので、楽しくなったかと思っています。
難易度想定としては、東方でいう Easy と Normal の中間ぐらいです。なぜなら私の腕前がそれぐらいだからです… (Normal で 1-2 コンティニューでクリアできるぐらい)
開発者補正で回避力が上がっている説はあるので、普通のプレイヤーにとっては Normal ぐらいになったかもしれません。
完全に別の話ですが、プレイ後の感想で「東方をやりたくなった」とあって若干嬉しくなりました。ちょうど新作 (虹龍洞) が出ているのでぜひ…!
ボス
一発ネタなので、おそらく繰り返してプレイしてくれる方は少ないでしょう。
したがって「覚えれば余裕だけど初見殺し」の戦略はなるべく回避しなければなりません。
そこで、 "caution!" 警告エフェクトを事前に焚いておくことで、驚かせつつキルはとらない程度のバランスになるようには気を付けていました。
5-6 面は警告があっても避けられない場合があるかもですが、そこは後半面なので許してもらって…
弾幕の設計にあたっては、攻撃に全く寄与しない(後ろとか左右遠くにすっ飛んでいく)弾を増やして、インパクトを確保しつつ実際そこまで難しくない、みたいなバランスにできれば… と思ってはいたのですが、実際はなかなか難しかったです。
作っているとどうしても「こうすればプレイヤーに当てられる」という方向に意識が持っていかれがちですね… 当てられて嬉しい人間は作者しかいないのですが…(なんならプレイをやめられたら作者にも損なのに)
東方を観察していると、弾にかなり細かく加速度が設定されていて (発射瞬間の速度は遅く(どの方向に来るか分かる)、急に加速して (プレイヤーが認識する速度になる) 、プレイヤー付近に来たころに減速する(認識していた速度より避けやすくなる)、といった) 、流石だなと思ったりしました。
設計上加速度をつけるのが若干面倒な感じになってしまっていたので、もし次があれば楽に加速できるようにしておきたいです。
また、今回特有の制約として「同時に大量に弾を出すと処理落ちする」問題がありました。大量にといっても 32 個とかのレベルでも若干怪しいです。
そのため、後期に作られたキャラ (アカネ/アスナ/ビナーあたり) は、螺旋状に出したり時間差で撃ったりというのを気を付けていました。
キャラごとに弾幕の方向性みたいなものを決めていました。
- ユウカ: バリア、数学っぽい(四角や円など)
- アカネ: 反射、爆発 (背後ではじける巨大弾のやつです)
- カリン: スナイパー(高速巨大弾)、曳光弾(弾から弾を出す)
- アスナ: 高速移動(スキルからの連想)、軌道が曲がる弾(つかみどころない感)
- ネル: 乱射、力技感
「げきこう」「コールサイン ダブルオー」あたりは調整の余地があったな、という反省があります…
激昂はもう少しプレモーションを増やしたり見た目上の綺麗さが出せれば… と
ダブルオーは轢かれる (回避した先に弾源が来る) 事故が多発していたので、うまいことできなかったな…と
ビナーの耐久弾幕 (浄化の嵐) は、「それっぽさ」を出すのにとてもいい感じになったと思います。ブルアカ本編でもかなり火力が高い攻撃で苦戦しましたし…
一応ノーダメージで抜けられることも確認してはいますが、まぁもう少しマイルドにしてもよかったのでは、と反省はあります… 最初の大縄跳びは普通に私も苦手です。
ところで、 1 面にユウカさんを置いたのは「ゲーム開発部が作ったなら多分そうするだろうな」という感じがあったからです。かにビーム先生のイラスト のアレとかの雰囲気で…
とても好きなキャラクターなので、雑に置いたわけではないです。念のため。 Extra とか作るならユウカさんにしていたかもしれません。
アイテム
いわゆる「得点アイテム」や「パワーアイテム」は最初から実装しない予定でした。というのも、元ネタよりも画面が狭く、半透明表現なども使えないので画面がごちゃごちゃしそうなため、またパワーアップの実装とバランス調整に手間がかかりそうだったためです。
ただ、いざ抜いてみると「敵や弾がまだあるのを避けながら、上に行って全回収する」とか、「ボスが落とした点符を速やかに回収してまた下に戻る」みたいな操作ができなくなってしまって少し退屈になってしまったので、よく考えられているな… と思いました。
エクステンドとスキルアップ(ボム)は、かなり大盤振る舞い目に設定しました。
おそらく繰り返しプレイはされずに負けたらそれきりでしょうから、多少残機が減ってもすぐに補充できるようにと思って増やしていました。せっかくなので最後まで見てほしいので…
プレイ感想を見るに、なんならもうちょっと増やしてもよかったかもしれませんね…
デザインとしては、セリナさんのスキルの救急箱がモチーフです。ただ 赤十字レギュレーション に引っかかる可能性が…?との杞憂のため、ハートアイコンにしておきました。調べた感じでは色反転は大丈夫そうでしたが。
あと、アイテムではないですがスコアについて…
ステージクリアのスコアがかなり大きめ (ラスボスまで行っても撃破点がだいたい 100 万行くかどうかのところ、ステージ x 100 万) になっているのは、結果ツイートからどれぐらいまで進めたかを推測しやすくするためです。
プロモーション
せっかくなので動画を撮影してツイートにくっつけることにしました。静止画では弾幕が伝わらないので…
動画撮影・編集環境がそもそもなかったので、構築から始めました。 2 日ぐらいかかって締め切り当日に差し掛かったので割と危なかったです…
撮影は OBS , 編集は AviUtl です。編集といってもクロスフェードさせただけですが…
動画はいつもは GameBar で撮っているのですが、枠の切り取りができなかったので艦これブラウザのデバッグで入れたまま放置されていた OBS を使いました。
環境構築を含めて結構手間だったので、世の動画勢各位はすごいなと思うなどしました…
動画制作時は、出し惜しみしないことを念頭に置いていました。
今回はネタバレよりもプレイされないことのほうがデメリットなので…
その点ではビナーはいい感じのサムネイルになったのではと思います。
プログラミング
開発は Unity 2021.1.3f1 で行いました。
ソースコードはこちらで公開しています。
コミットログを眺めてもらうと開発の雰囲気が分かるかもしれません。
以下、使ってみたライブラリや機能の所感を書いていきます。
UniTask
非同期処理を簡潔に書けるようにするライブラリです。
このプログラムの中核をなしています。ほぼすべてのスクリプトで using しています。
というのも、今回の制作における重要な目的のひとつが「UniTask v2 に慣れる」だったためです。
基本的に Unity 標準のイベントは Start だけ使って、他 (OnTriggerEnter2D, Button.onClick など) は UniTask に用意された要素で実装しています。
UniTaskAsyncEnumerable がかなり使い勝手が良かったです。
雑に説明すると、普通の for 文が空間方向の繰り返し (円形のような) であるのに対して、これを使うと時間方向にも簡易に繰り返す (例としては螺旋など) ことができます。
詳しくはソースコードを参照してもらうのが早いのですが、例えば、螺旋状に弾を撃つ攻撃 (アカネの初回攻撃) は、以下のように実装できます(エフェクト等は省略しています):


async UniTask Phase(float direction, CancellationToken token)
{
float baseRadian = Seiran.Shared.NextRadian();
int ways = 24;
await UniTaskAsyncEnumerable.Timer(TimeSpan.Zero, TimeSpan.FromSeconds(0.05), PlayerLoopTiming.FixedUpdate)
.Select((_, i) => i)
.Take(ways)
.ForEachAsync(i =>
{
var bullet = BulletBase.Instantiate(m_NormalShotPrefab, transform.position, BallisticMath.FromPolar(32, baseRadian + i * Mathf.PI * 2 / ways * direction));
}, token);
}
とても簡潔に書けます。
並列実行も簡単で、「動きながら撃つ」も await (Move(token), Shot(token)); と書くだけで実現できます。
これのおかげで移動コードと射撃コードを別々に実装することが可能です。
また、 "HP が 0 になったら、攻撃を中止して次のフェーズに移る" といった処理は、キャンセル機構を使用して実装しています。
var destroyToken = this.GetCancellationTokenOnDestroy();
var hpTokenSource = new CancellationTokenSource();
using (var combinedTokenSource = CancellationTokenSource.CreateLinkedTokenSource(destroyToken, hpTokenSource.Token))
{
var combinedToken = combinedTokenSource.Token;
await action(combinedToken).SuppressCancellationThrow();
}
こうすると、(action() を適切に実装していれば) HP が 0 になった瞬間に上のブロックを抜けて、次のフェーズの処理に進むことができます。
初心者向け(?)逆引き
一番最初にあれば助かったな、と思うシリーズです。
文献としては https://qiita.com/toRisouP/items/8f66fd952eaffeaf3107 がとても詳しいですが、前提知識が割と必要な気がしたので、雑に使いたい人は下を見てみるとよい…かもです。
※ 間違っていたらマサカリを投げてください
(m 秒後から) n 秒ごとに繰り返したい
await UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.ForEachAsync(_ => { }, token);
await foreach(var _ in UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.WithCancellation(token)) {
}
フレーム単位なら TimerFrame が、毎フレームなら EveryUpdate が使えます。
また、 FixedUpdate 相当のタイミングで実行したい場合は PlayerLoopTiming.FixedUpdate を引数に渡すことで実現できます。
やりたい処理が非同期なら、以下が使えます。
(2 秒動く → 1 秒待つ → ... など)
await UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.ForEachAwaitWithCancellationAsync(async (_, token) => {
await Move(token);
}, token);
await foreach(var _ in UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.WithCancellation(token)) {
await Move(token);
}
一定回数の繰り返し
await UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.Take(x)
.ForEachAsync(_ => { }, token);
LINQ が使えます。
何回目のループか知りたい (for 文の i が欲しい)
await UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.Select((_, i) => i)
.ForEachAsync(i => { }, token);
別のシーケンスが使いたいときは、
static IEnumerable<float> Linear(float start, float end, int way)
{
for (int i = 0; i < way; i++)
yield return Mathf.Lerp(start, end, i / (way - 1f));
}
await UniTaskAsyncEnumerable.Timer(timeSpanDelay, timeSpanInterval)
.Zip(Linear(128, -128, density + 1).ToUniTaskAsyncEnumerable(), (a, b) => b)
.ForEachAsync(y => { }, token);
投げっぱなしにする
var bullet = BulletBase.Instantiate(...);
UniTaskVoid MoveBullet(BulletBase bullet, CancellationToken token) { ... }
MoveBullet(bullet, bullet.GetCancellationTokenOnDestroy()).Forget();
キャラ側で弾の特殊挙動を記述する際など、出したらそれっきりで以降放置するような場合に便利です。
(弾側に記述しろ、はまぁその通りではあるのですが…)
キャンセル周りについて
実装において、慣れが必要なのはキャンセルの部分です。
このエラーメッセージを無限に見ました。


コルーチンと違って GameObject が Destroy されても UniTask のコードは動き続けます。
例えば安直に await UniTask.Delay(5000); としてしまうと、待機中に Destroy(gameObject) された場合、後続のコードで破壊済みの this や transform を参照して落ちます。
したがって、必ずキャンセル処理を実装する必要があります。
具体的にどうするのかというと、
- 呼び出しの大本で
this.GetCancellationTokenOnDestroy() を使って Destroy 時にキャンセルされるトークンを生成する
- もし別のキャンセル事由がある場合は (HP が 0 になったとか)、上に書いたように
CancellationTokenSource.CreateLinkedTokenSource で合成できる
- そのメソッドから呼び出す非同期メソッド すべて に
CancellationToken を 必ず 渡す
- 子孫にもそのまま渡していく
UniTaskAsyncEnumerable.Timer などは .WithCancellation(token) (await foreach の場合) や .ForEachAsync(..., token) (メソッド呼び出し式の場合) で渡す
UniTask(Void) を返す非同期メソッドを自分で実装するときは、必ず CancellationToken を引数に含める
という感じです。
すごい量の cancellationToken: token を書くことになりますが、怠ると予期しないタイミングでエラーになるので横着せずに書いていきました。
また、トークンを渡し忘れると上に書いたエラーだけでなく「撃破したのに弾を撃ち続ける」なども起こります。
必ずキャンセルを意識するようにしなければなりません。
DOTween の待機について
UniTask の機能で Tween を待機することができますが、その際の注意点です。
まず、 DOSpeed() (弾速を変更する; ≒加速度設定) が DOTween.To を使って定義されているとして、
public DG.Tweening.Core.TweenerCore<Vector3, Vector3, DG.Tweening.Plugins.Options.VectorOptions> DOSpeed(Vector3 endValue, float duration)
=> DOTween.To(() => Speed, value => Speed = value, endValue, duration)
.SetEase(Ease.Linear)
.SetLink(gameObject);
段階的に加速させるコードを以下のように書いたとしましょう。
最初にちょっとだけ加速して予兆を見せてから、一気に加速するイメージです。
await bullet.DOSpeed(BallisticMath.FromPolar(32, radian), 1);
await bullet.DOSpeed(BallisticMath.FromPolar(192, radian), 1);
するとこれを引きます。
1 行目の実行中にスキルなどで bullet が Destroy されると、 2 行目で bullet が参照できなくなるので落ちます。
(厳密には、 DOTween.To の getter を参照されたタイミング辺りで落ちます。)
まぁ CancellationToken を渡していないせいだろうと、これに変えます。
await bullet.DOSpeed(BallisticMath.FromPolar(32, radian), 1).WithCancellation(token);
await bullet.DOSpeed(BallisticMath.FromPolar(192, radian), 1).WithCancellation(token);
するとこれを引きます。
何がいけなかったのかというと、 .WithCancellation(token) は .ToUniTask(TweenCancelBehaviour.Kill, token) と同じ意味になるのですが、 この TweenCancelBehaviour.Kill の場合、キャンセルされた際でも OperationCanceledException が飛ばないようです。
その結果、 1 行目がキャンセルされてもそのまま 2 行目に実行が継続されて落ちてしまっています。
したがって、飛ぶように KillAndCancelAwait を指定してあげればよい、というわけです。
await bullet.DOSpeed(BallisticMath.FromPolar(32, radian), 1).ToUniTask(TweenCancelBehaviour.KillAndCancelAwait, token);
await bullet.DOSpeed(BallisticMath.FromPolar(192, radian), 1).ToUniTask(TweenCancelBehaviour.KillAndCancelAwait, token);
こうすれば、 1 行目の実行中にキャンセルが走った場合、きちんとキャンセル例外が飛んで実行が中断され、 2 行目に進まなくなります。
まとめ
キャンセル周りの手間をかけたとしても、全体的にすごく楽に書けるので良かったです。なんなら公式で組み込みにしてくれてもいいのでは、と思うレベルの必要度でした。
あと Unity の非同期はほぼシングルスレッドなので、WinForms のように UI スレッドに切り替えないでコンポーネントに触ったら落ちる、みたいな地雷が少ないのも初心者にはやさしいです。
まぁ習熟は必要で、実際私が初期に書いたコードは若干怪しい感じになっており、少し慣れた今リファクタリング(バグ修正?)してもいいかもしれませんね…
Input System
Unity の新しい入力管理システムです。
導入の利点などは https://forpro.unity3d.jp/unity_pro_tips/2021/05/20/1957/ に詳しいです。
(ちょうどこの記事を書いているときに見つけました…)
ただ、何度も地雷を踏んだので、あまり印象が良くないです… プロダクトに使うにはまだ不安定なのでは、という印象がありました。(私が不慣れなだけの可能性はあるので、 Input System マスターの方がいらっしゃったらすみません)
旧 Input の使い方がわかっている方は、 移行用のドキュメント があるので見るのが早いです。
以降、私が爆発したポイントを列挙していきます。
Input.GetKeyDown|Up() 互換が (Stable 版には) ない
2021/05/21 現在の最新 Stable 版 (1.0.2) には、上記メソッド互換の機能が存在しません。…存在しません!!
近いものとしては、 input.Player.Fire.started|performed イベントと設定を駆使する方法で取れなくはなさそうです。しかし、設定が難しい(挙動がどう変わるのか分かりにくい)うえ、 event なので扱いが難しいです。
他には、 Keyboard.current.aKey.wasPressed|ReleasedThisFrame があり、こちらはプロパティなので自然に使えます。しかし、これはキーを直接指定するものであり、ゲームパッド等々との併用には使えません。せっかく手間をかけて入力を仮想化した意味が薄れてしまいます。
Preview バージョン (1.1.0-preview.3) には input.Player.Fire.WasPressed|ReleasedThisFrame() が実装されており、これが GetKeyDown|Up() 互換で使えます。したがって、 Preview 版を入れる必要があります。
(Package Manager からは指定できないようなので、 manifest.json を直接書き換えて導入します。)
あまりにも基本的なメソッドが欠けているので、旧 Input に戻したほうがいいのでは…? という強い誘惑にかられました…
Keyboard.current は null になりうる
先の記事にはちゃんと書いてありましたが、私は知らなかったので…
キーボードが繋がっていたとしても、 Scene のロード中などに一時的に null になる場合があります。そのため、必ず null チェックを入れる必要があります。
デバッグコマンドだから Keyboard.current で直指定でもいいや、としていると引っかかりがちなので注意です。
エディタ上で再生開始時に一切の入力を受け付けなくなる
再生開始時に、ランダムにキーボード・クリックその他すべての操作が無視されるようになります。
Input Debug ビューからのキーテストは反応しますが、 Game ビューには反映されません。
これはいまだに原因がわかっていません…
ワークアラウンドは「Hierarchy ビューで InputSystemUIInputModule (EventSystem ?) がアタッチされているオブジェクトを選択する」です。なぜかは分かりませんが、以降操作できるようになります。
もし解決策をご存じの方がいらっしゃればご一報ください…
情報が薄い
一番致命的なやつです…
採用例が少ないので、公式のマニュアル(英語)を見て、分からなければフォーラム(英語)を巡回する羽目になります。
「導入してみた」記事は日本語でもよくありますが、実用してみた場合はあまりなかったりするので…
良かった点
dis るだけ dis ってもアレなので、良かった点を書きます。
まず、 キーボード/ジョイパッド 等々への対応はとても楽です。デフォルト設定も存在しており、コピペすれば概ねいい感じに対応できます。
また、スマートフォン対応用の On-Screen Button/Stick が標準で実装されており、スクリプトを貼るだけで「タップすると Z キー相当のイベントが走るボタン」「ドラッグで Left Stick 扱いされるスティック」が実装できます。
雑にスマートフォン対応するだけならあっという間です。
加えて拡張性もあります。今回はショットボタンをトグル形式 (押しっぱなし扱いになるボタン) にしましたが、以下の短いスクリプトを書いて貼り付けるだけです。
[RequireComponent(typeof(Toggle))]
public class OnScreenToggle : OnScreenControl
{
private Toggle m_Toggle;
[InputControl(layout = "Button")]
[SerializeField]
private string m_ControlPath;
protected override string controlPathInternal { get => m_ControlPath; set => m_ControlPath = value; }
private void Start()
{
m_Toggle = GetComponent<Toggle>();
m_Toggle.onValueChanged.AddListener(value =>
{
SendValueToControl(value ? 1f : 0f);
});
SendValueToControl(m_Toggle.isOn ? 1f : 0f);
}
}
2D Pixel Perfect
今回のようなレトロチックなゲームを実装するにあたり必須になるコンポーネントです。
カメラにアタッチするだけで Sprite の (見た目上の) 位置を整数にそろえてドットがくっきり表示されるようになり、かつ Pixel Perfect に拡大してくれるようになります。
UI と併用するときに少しだけ注意が必要で、 Custom Canvas Scaler を Canvas にアタッチしたうえで、 Canvas を Screen Space - Camera にする必要があります。 (やらないと UI 側と Sprite 側で描画がずれます。)
Custom Canvas Scaler は同梱されていませんが、 GitHub にあります。
Tilemap
その名の通りタイルマップです。今回は背景に使用しました。
かなり直感的なエディタがついているので、ほとんど迷わずに制作できました。
強いて問題を挙げると、そのままだと半グリッドだけずれている (16x16 のタイルなら、オフセットが (8, 8) になっている) ことです。これは Tilemap コンポーネントの Tile Anchor を (0.5, 0.5) から (0, 0) にすれば直ります。が、今度はエディタで塗るときにカーソルが半グリッドずれるので、編集時は (0.5, 0.5) にして終わったら (0, 0) にするというちょっと面倒な運用をしていました。
あとはアセットが大量に生成される (スプライト単位ではなくタイル単位なので、 1 枚の画像に 16 個タイルを置いていた場合でも 16 個アセットができる) のがちょっと… となるぐらいでしょうか。これは単に気持ちの問題ですが。
Google Spreadsheet と連携するものです。ステージの雑魚敵を設定する際、シートのデータ → ScriptableObject の設定値に変換するために使いました。(もちろんエディタ専用です。)
ScriptableObject において配列の直編集は相当な苦行なので、ステージエディタなどをする場合はほぼ必須だと思います。
(ローカルの CSV をいじれる環境があれば CSVReader 実装でいいかもしれませんが、 Office がないので…)
実装は StageDataEditor.cs にあります。導入もコメントに書いたので良ければ参考にしてください。
client_secret.json の生成 (アクセス権の獲得) が若干手間かもしれませんが、それだけの価値はあります。
シートの中身はこんな感じで、


Unity 上でこのボタンを押すと Enemies がシートに合わせて設定されます。


今回の機能は「位置を決めて Instantiate するだけ」でしたが、弾の動きとか HP とかも記述できるようにしておけばバリエーションを増やしやすかったかも、という反省があります。Prefab Variant を生産し続けてゴリ押しして終わらせてしまいました…
なお、導入にあたって Visual Studio の nuget パッケージ管理から直接突っ込むとうまく動作しませんでした。
別のプロジェクト (WinForms とか) でダウンロードしてから、バイナリ *.dll だけを Editor フォルダ下に突っ込む手法で動かしていました。
この時、 netstandard2.0 のものだけ入れるようにしましょう。同名の *.dll が複数あると Unity がエラーを吐きます。
また、毎回の注意点として、 client_secrets.json といった機密情報は git に含めないように十分注意が必要です。
Addressable Asset System
悪名高い Resources/AssetBundle の後継です。
今回は AssetBundle のように本体と分割して扱うことは考えていなかったので、いわば "Better Resources" のような運用をしていました。本来の使い方ではないかもですが…
運用としては、Inspector でチェックボックスを入れればパスが得られるので、それを
var prefab = await Addressables.LoadAssetAsync<GameObject>("some/prefab/path.prefab");
とするだけで読み込めます。 Resources と使用感はほとんど変わりません。 UniTask があるので await もできます。
注意すべき点としては、 WebGL ビルドする前に必ず Addressables もビルドする必要があることが挙げられます。何度となく忘れて古いアセットがロードされました…
一時はビルド前に自動で Addressables ビルドが走るようにエディタスクリプトに書いておいたのですが、いつからかビルドに失敗するようになってしまったので結局手動でビルドしていました。うまく自動化できるとよかったのですが…
謎の OnJointBreak2D エラー
一番最初に直面したのがこれです。
Development Build は正常に成功するのですが、実行して InGame に入ると以下のエラーがコンソールに出て、動作が不安定になります。
Script error: OnJointBreak2D
This message parameter has to be of type: [UNREGISTERED]
This message will be ignored.
これは UniRx を入れており、かつ Project Settings の Strip Engine Code が有効になっていると発生します。 UniRx 側で Joint2D を参照しているにもかかわらず、ビルド時に未使用判定を受けて Joint2D のコードが削除されてしまい、実行時エラーとなります。
(UniRx は悪くないです、念のため)
これを防ぐためには、ルートの Assets フォルダ直下に link.xml というファイルを作成し、こんな感じに記述します。
<linker>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Joint2D" preserve="all" />
<type fullname="UnityEngine.Collider" preserve="all" />
<type fullname="UnityEngine.BoxCollider2D" preserve="all" />
<type fullname="UnityEngine.CircleCollider2D" preserve="all" />
</assembly>
<assembly fullname="Unity.ResourceManager, Version=0.0.0.0, Culture=neutral, PublicKeyToken=null" preserve="all">
<type fullname="UnityEngine.ResourceManagement.ResourceProviders.LegacyResourcesProvider" preserve="all" />
<type fullname="UnityEngine.ResourceManagement.ResourceProviders.AssetBundleProvider" preserve="all" />
<type fullname="UnityEngine.ResourceManagement.ResourceProviders.BundledAssetProvider" preserve="all" />
<type fullname="UnityEngine.ResourceManagement.ResourceProviders.InstanceProvider" preserve="all" />
<type fullname="UnityEngine.ResourceManagement.AsyncOperations" preserve="all" />
</assembly>
<assembly fullname="Unity.Addressables, Version=0.0.0.0, Culture=neutral, PublicKeyToken=null" preserve="all">
<type fullname="UnityEngine.AddressableAssets.Addressables" preserve="all" />
</assembly>
</linker>
これでビルドすると、 fullname で指定したクラスがビルドに確実に含まれるようになり、うまくいきます。
(Joint2D 以外でも Collider や Addressables で似た事象が起きたので追加してあります。)
Strip Engine Code を無効にする手もあり、もちろんそちらのほうが手軽ですが、副作用があるので可能なら上の手段をとったほうがよさそうです。
エディタが重い・ビルドが重くて長い
こればかりはどうしようもないですが…
スクリプトを変更するたびに 10-15 s ぐらい待たされます。リリースビルドに至っては CPU をフルに消費した状態で 10-12 分程度かかります。なかなかしんどいです…
また、エディタ実行時の重さもだいぶひどいです。なんなら 1 fps になることもしばしばありました。
この辺りは私の実装が悪い説も大いにあるのですが、だとしてもしんどいです。
(これに関しては、何かのプロファイリングを知らぬ間に有効にしてしまっていた説もあります…)
GameObject のキャッシュ機構とかを作るべきだったな、とはずっと思っていました。思っていたら期間が終わりました…
逆に言えば、最適化のしがいはありそうです。
今回は公開場所を GitHub Pages にしたのですが、そこでは Project Settings の Compression Format を Disabled にする必要があります。 Brotli や Gzip だと起動時にエラーが出ます。
(また、記憶が怪しいですが確か Brotli にすると localhost での実行時でもエラーが出ます。)
というのも、 Brotli や Gzip にした場合はサーバ側で配信する際に設定が必要らしいです。自前サーバならよしなに設定すれば OK なのですが GitHub Pages では設定しようがないので Disabled にして回避します。
ツイートボタンを置きたい
Twitter の民としては、ゲーム内にツイートボタンを置きたくなります。
リザルトをつぶやけるようにしておけば、プレイヤーがクリアしてくれたか分かってとても嬉しくなります。(ありがとうございます。)
ただ、ここで問題があります。
エディタでは Application.OpenURL(string url) を呼ぶだけで対応する URL を開くことができます。しかし、ビルド (ブラウザ上) でこれを実行すると、見事ポップアップブロックに弾かれます。スマートフォンのブラウザの場合、ブロックされたことすら通知されず握りつぶされます。
原因はというと、現代のブラウザでは邪悪なポップアップを防ぐため、ユーザ起因のアクションでのみポップアップを開くことができるようになっているためです。
(これ自体はもちろん正当な処理です。)
そして、Unity 内のボタンをクリックした際、入力から実際に反応する (uGUI の onClick イベントが呼ばれる) までには若干のラグがあります (ほんの少し非同期になっているイメージです)。すると「ユーザ起因のアクション」でないとみなされ、ブロックされてしまいます。
これを回避するためには、 js レイヤーのイベントを利用してウィンドウを開かなければなりません。そのための仕組みが用意されています。
(公式マニュアル)
まず、 Assets/Plugins/ のどこかに以下のスクリプト (TweetPopup.jslib) を用意します。
// note: keyup イベント上での発行は IE, FireFox では popup block に引っかかる
// が、タイミングを合わせる意味でもここに書いておく
// (クリックでもイベントが消費されるので、意図通りに操作すれば出ない…はず)
mergeInto(LibraryManager.library, {
RegisterPopupEvent: function(url) {
var resolvedUrl = Pointer_stringify(url);
var open = function(event) {
if (!(event instanceof MouseEvent) && event.key != "z")
return;
window.open(resolvedUrl);
document.getElementById('unity-canvas').removeEventListener('click', open);
document.removeEventListener('keyup', open);
};
document.getElementById('unity-canvas').addEventListener('click', open, false);
document.addEventListener('keyup', open, false);
}
});
そして、 C# コードからはこのように呼び出します。
#if UNITY_WEBGL && !UNITY_EDITOR
[DllImport("__Internal")]
private static extern void RegisterPopupEvent(string url);
#endif
public void RegisterTweetEvent(string url)
{
#if UNITY_WEBGL && !UNITY_EDITOR
RegisterPopupEvent(Uri.EscapeUriString(url));
#else
Application.OpenURL(Uri.EscapeUriString(url));
#endif
}
すると、 RegisterTweetEvent() を実行したあと、次にクリック/キー入力されたとき、指定した URL が別窓で開くようになります。Twitter 用の URL パラメータは マニュアル や "Twitter Intent" で検索してください。
ただし、 //note: に書いた通りキー入力経由でポップアップさせた場合は、環境によってはブロックされてしまいます。ブロックされないイベントは非常に限定されており、どのブラウザでも通るのは click ぐらいで、 keydown/up などのキー関連イベントでは環境依存 (少なくとも FireFox では全面的にダメ) なようです。
これは仕様なので回避策はありません。諦めましょう。
また、スマートフォン環境ではまた別の手法 (twitter:// インテントを使ってアプリを開くなど) が必要らしいです。今回はそこまでしませんでしたが…
もともと想定環境ではありませんが、そのままだと「ボタンはタップで押せるので InGame までは進めるが、以降キー入力ができずただ殴られるだけになり終了」という大変ユーザー体験の悪い状態になるので、最低限操作できるようにだけはしておきたいです。
スマートフォン上での入力エミュレーションについては Input System の項で述べたとおりです。
あと必要なのは、操作用 UI を出し分けるためにスマートフォン上で動作しているかを検出することです。これは、twitter ポップアップの項と同じように IsMobile.jslib を作って、
mergeInto(LibraryManager.library, {
IsMobile: function() {
return Module.SystemInfo.mobile;
}
});
として、同じ要領で IsMobile() を C# スクリプト側から呼べばよいです。
UnityLoader.SystemInfo.mobile としている文献がよくヒットしますが、そちらは現在の Unity バージョンでは廃止済みなので実行時エラーになります。今は代わりに Module が使えます。
もっと単純に Application.isMobilePlatform でとれるかも?という話も見かけますが、うまくいかなかったような気がします(記憶があいまいなので、一度試してみるとよさそうです…)
ところでリリース後の話ですが、やはりというかスマートフォン上で起動したユーザーが少なからずいたようなので、この工夫は無駄ではありませんでした。備えあれば憂いなしです。
グラフィック
グラフィック担当の私です。画像作成の際に気を付けていたことなどを書きます。
全体的な傾向
まず、テーマはレトロチックです。ファミコンぐらい想定です。
(ぐらいというのは、厳密に色数やスプライト数を制限したりすると可視性やデザインセンスの面で厳しいので…)
ということで、以下のレギュレーションを設けました:
- 半透明禁止
- 代わりにディザリングやカットアウトを使います
- 雑にフェードイン/アウトさせたり、境界をぼかしてごまかしたりできないので、一番つらかったかもしれません
- 加算合成禁止
- 回転禁止
- 2D Pixel Perfect がよしなにしてくれるとはいえ、見た目がよくならなさそうだったため
- 自機の弾は例外です(超高速で目立たないかと…)
- 1 スプライトの色数を 2-4 色程度に抑える
また、目には見えないところですが、なるべくスプライト自身のサイズを削る工夫をしていました。
もともと小さいのでパフォーマンスとかファイルサイズは誤差みたいなものですが、なんというか「レトロチック」なので…
例えば、下のようなボタンの背景は 8x16 のスプライトを 9slice で引き延ばして利用しています。


ツールは GIMP を使用しています。
アニメーション
全体的に、左右非対称に描いたうえで左右反転させて差分を作り、 2 コマのアニメーションにする手法を使っていました。
手間を減らしつつ最低限アニメさせることができてよいです。
止まっているよりはだいぶ工夫感が出る…はず…
消滅していくアニメーション ("Start!" など) を描くにあたり、 GIMP の消しゴムレイヤー (塗ったところが消える) が便利でした。いちいちレイヤー結合しては削除して… といったフローが不要になります。
キャラクターグラフィック
最初は「双子ならほぼ色変えだけで済むので、双子中心で作って余力があればアリスを」といった感じだったのですが、途中でスプライトを全入れ替えするわ(後述)、ブルアカ本家の実装祝いにユズさんまで実装するわで普通に工数が重かったです。でも楽しかったです。
メイド部もコスチュームが近いので楽…かと思いきや、よく見るとバリエーションに富んでいたので輪郭ぐらいしか流用できませんでした。ドット絵の練習にはなりましたね…
あと、余裕があればクリア画面に専用ポーズの画像を出したりしたかったのですが、まぁ時間的に無理でした…
// あと、こういったテーマ企画の際は、三面図みたいなものを 3D モデルのキャプチャでいいので公開してほしい気持ちになりました。自機の背中を書きたくても資料がなく、ストーリーの出撃イベントを巡っては小さなちびキャラの背中を観察していました…
背景スプライト
以下のような画像を使っています。制約があったほうがそれっぽいかな… と思い、1 ステージ当たり 16 枚分にしました。色数も 1 枠当たり 2 色に抑えています。


工場のフックのケーブルと箱の胴体は、実は同じスプライト (上の画像の 8 番目) です。ファミコンとかでこういうのしがちなイメージがあったので勝手にテンションが上がりました。言わないと誰も気づかないと思うので書きます。


基本的に「背景」なので、弾や敵の認識の邪魔にならず、かつキャラの色にかぶらないようにするのがかなり難しかったです。特にユウカさんは #000080 と #FFFFFF を併せ持っていて、かつ #00FFFF のバリアまで撃ってくるので、明るくても暗くても目立たなくなり大変でした…
UI
可能な範囲で本家っぽくなるようにしました。ボタンの形と三角形の飾りぐらいですが…
あとは「そもそもの画面数と遷移を減らそう」が方針としてありました。画面と遷移が増えるとその分バグと工数が増えるので、本当に最低限としました。ポーズはフォーカスアウトで、タイトルに戻るは F5 でできます…!
また、こういった短時間だけ遊ぶゲームは操作分からなくなりがち問題があるので、最初に「このボタンがこれ」と表示して終わり、ではなく、常に画面下とか右に「何キーが何なのか」を書いておくようにしていました。 Apex Legends とかその辺り親切ですよね…
UI といえば、フォントは大切ですね…
最初は PixelMplus のフォントを使っており、ターミナルらしくて味が出てはいたのですが、 MS ゴシック 感がすごかったので、ゲームらしいフォントに途中で入れ替えました。
名残が "Warning!" エフェクトなどにみられるかと思います。
ただ、変えたら変えたでフォントの横幅がだいぶ異なり (半角と全角ぐらい違います)、今まで収まっていたテキストがはみ出したりして大変でした。フォント選定は最初期に慎重に行いましょう…
フォントといえば、 TextMeshPro の RASTER モードではシャドウや囲みができないようです (SDF 限定)。
もしやりたければ最初からテクスチャに焼きこむとかでしょうか…?
一番難しかったのがこれだったかもしれません。
BGM
"Andante" とかいうユーザー名をしておきながら音楽的素養がほぼ 0 なので、耳コピするだけでも大変でした。
なるべく耳コピしやすく、かつ使いやすくて印象的な曲を… ということで、タイトルとビナー戦の BGM をチョイスしました。
(ビナー戦は印象的な繰り返しのフレーズが多く、それっぽくしやすかったので大変助かりました…)
本当は通常戦闘曲や勝利ジングルも入れて BGM 切り替えをしたかったのですが、私の能力では限られた時間内にとても再現しきれなかったので諦めました…
ちなみに、サウンドは「ピストンコラージュ」で作っています。洞窟物語などで使われているツールです。
最初は Domino でやろうかと思ったのですが初期音源があまりにも貧弱でそれっぽくならず (それはそう)、どうしようかと思っていたら HDD の奥底からこのツールが見つかったのでこれで行きました。10 年ものとかです…
ファミコン感を出すために 25%/12.5% 矩形波の素材を作ったりもしました。それっぽく聴こえてかなりテンションが上がったのを覚えています。
SE
SE も自作です。同じくピストンコラージュ製です。
爆発音はだいたいドラムやスネア、UI の「ピ」などは単発の矩形波音などでできています。
反射音とかボスアラートがちょっとうるさかったかな、という反省があります…
また、プログラミングセクションの話かもですが、 SE の再生優先度を設定していれば… とリリースしてから思いました。
アリスさんのスキル SE や被弾音がかき消されてしまう場合があったので…
同じくプログラミング的な話ですが、 SE には一応同時発声数制御を入れてあります。最大 8 枠で、オーバーしたら古い順に停止・上書きされる仕組みです。また、同一フレームで同じ音が鳴った場合には再生しない処理も入っています。
WebGL 環境では結構発声数の制約が厳しく、あまりたくさん鳴らすとすごいノイズが出たかエラーを吐くかしていたので (記憶があいまいです)、そもそもそうならないように制限を入れていました。
The Cutting Room Floor
いわゆる「没画像集」のコーナーです。供養のためと、私は TCRF が大好きな人種なので…
自機 (16x16)


もともとは自機が 16x16 だったのですが、ディティールがつぶれてスプライトが描きづらい・誰か判断しにくい問題があったため、現状の 32x32 に描き直しました。ユズさん実装時点では 32x32 に移行済みだったので、ユズさんの分はありません。
それにあたり、流石に当たり判定がわかりにくくなったので、当たり判定表示 (赤丸) を追加したりしました。ユズさんだと色が近いので見にくかったりしますが…
壁際に立つとめり込むのは 16x16 時代の名残です。
敵弾


これらもありましたが、それぞれ以下の理由で没になりました。
- (緑弾) イメージに合うキャラがいなかった
- (二重円弾) 東方っぽくなりすぎる (個人的に一番好きなデザインなので入れたい気持ちはありました)
- (粒弾) 見えない!!
あまりカラフルにしても(デザイン上の問題 (レトロゲーム感) とか工数とか工数とか…)という気持ちがあったので、今回は色数を抑えめにしました。
NES (ファミコン) の解像度 256x224 (うち、フィールドは 176x224) にした都合上画面がだいぶ狭いので、サイズがそれぞれ小さめになっています。
弾といえば、進行方向が分かる弾(楕円形とか、鱗弾とか)を入れたい気持ちはあったのですが、 Pixel Perfect である関係上うかつに回転させると見た目がよくなさそうだったので、すべて円形弾としました。


ユウカさんのバリアの自機が通れないバージョンです (当たると弾が消えます)。完全に動作しますが使っていません…
当初はブルアカ本編のように、遮蔽に隠れつつ射撃するようなシチュエーションがあってもいいのでは、と作っていました。
背景スクロールに合わせるとすごく移動が遅くなるので、使いどころが難しく没になりました。
ユウカ(左右移動)


上二つは使用したスプライト、下二つが左右移動用のスプライト(未使用)です。
よく見ると髪や足が動いています。
使うのを忘れていました… 最も、時間的に全員分作るのは厳しかったかとは思います。
当たり判定バグ
リリースが完全に終わって、土曜日になってから気づいたのですが…


緑の円がモモイさんと敵弾の当たり判定です。 (他のキャラ・色でもサイズは同じです)
モモイさんは二重円になっていますが、内側の当たり判定表示の白い円とほぼ同じサイズのものが被弾判定、外側の大きな円が物理判定(前述のバリケードに侵入できないようにする判定)です。…そのはずでした。
実際のところ、物理判定 (外側の円) に当たることでも被弾します。想定半径の 3 倍です……
OnTriggerEnter|Stay2D() 、isTrigger なものだけに反応すると思ったらそうではないんでしたね… 忘れていました…
それでめちゃくちゃ当たっていたようです。申し訳ないです…
試しに修正した状態で "浄化の嵐" を受けてみたところ、すんなり突破できてしまいました…
今直すのはレギュレーション的にどうなのだろうというのと、難易度がそこそこ変わりそうなので (本当に開発初期からこの状態だったので、これ前提で弾密度を組んでしまった)、一旦そのままにしておきます…
ポジティブに考えると、弾数少なめで圧迫感が出るのでまぁ良かったのではないでしょうか…
Debugging Functions
ゲーム内の Info に書いたものですが、ここにも残しておきます。
- F8 キーを押すと高速周回モード (3 倍速) になります
- Player Select 画面で ↑↑↓↓←→←→XZ すると、
- デバッグモードになります
- 被弾しても HP が減らなくなります
- スキルを撃っても減らなくなります
- スコアがアビドス状態になります (不正防止のため)
- 入力に成功すると爆発音が鳴ります
- ユズ以外を選択する場合は、Z を押す前にカーソルを動かしてください
- Player Select 画面で 1~6 キーを押しながら開始すると、対応したステージから開始します
おわりに
という感じで作っていました。久しぶりのゲーム制作でしたがとても楽しかったです。
この記事を書き終わる前に結果が出てしまいました。
「特別賞」を頂きました。
まさか本編のシナリオに合わせてくるとは思わず震えていました。ありがとうございました。
また、プレイしてくださった方々にも大きな感謝を…。少しでも楽しい時間になったら幸いです。
「ブルーアーカイブ」本編ももちろん楽しいゲームですので、もし初めて興味を持った方がいらっしゃればぜひ…!
「ゲーム開発部」のメンバーがメインストーリー Vol. 2 で活躍しています。
https://bluearchive.jp/